Our New Direction
As we progressed from the initial phase of our project, we began with the goal of developing a model to predict cryptocurrency prices. However, we encountered several challenges that highlighted the limitations of this approach, which included the objective definition of sentiment, whether correlation necessarily exists between the sentiment on Reddit and prices, and most importantly, whether our model actually identifies and aggregates the sentiment correctly in the first place. Hence, after careful consideration, we've decided to shift our focus to creating accurate methodologies first. Those methodologies would judge the underlying sentiment of each item obtained and allow us to get an aggregated picture for a certain time frame using a scoring method, where 1 = positive, 0 = neutral, -1 = negative.
Our new idea, as visualised in Figure 1, is an application that allows users to choose between different cryptocurrencies and sentiment sources for eventually running a sentiment-based trading simulation on a cryptocurrency for a selected period of time. Based on the sentiment score obtained for each day, the trading simulator will make a buy or sell decision. This will allow one to test whether it makes sense to make trading decisions based on sentiment at all. If it makes sense, the application will further help with developing a trading strategy. Should it not make sense, the application can serve as a useful example of why one should not care about the sentiment too much. Moving forward, the ultimate goal would be to develop the application in a way that one can investigate the sentiment of a given cryptocurrency and determine an optimal trading strategy based on that sentiment.
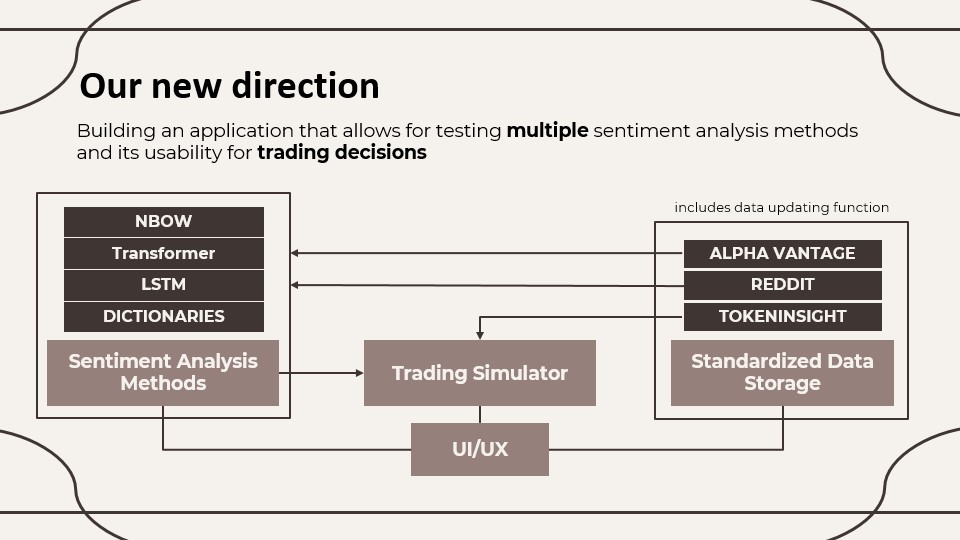
An especially important part of the application is the data updating function, that uses APIs to collect all the required data available with only one click up until the previous day and preprocesses it to a standardized format for the sentiment analysis. Under the hood, it includes the following functions (shortened):
a) Function that updates sentiment data
# Directories
PRICE_DIR = "P2_Data_Analysis/Pricedata"
SENTIMENT_DIR = "P2_Data_Analysis/Sentimentdata"
# Cryptocurrencies and their names/tickers
COIN_MAP = {
"binance-coin": ["binance coin", "binance", "BNB"],
"bitcoin": ["bitcoin", "BTC"],
"ethereum": ["ethereum", "ETH"],
"solana": ["solana", "SOL"],
"cardano": ["cardano", "ADA"],
"dogecoin": ["dogecoin", "doge", "DOGE"],
"ripple": ["ripple", "XRP"]
}
# [Code outtakes, a lot of functions]
# Main process
def main():
# Test authentication
print("Testing authentication...")
try:
print(f"Authenticated as: {reddit.user.me()}", flush=True)
except Exception as e:
print(f"Authentication failed: {e}", flush=True)
exit()
# Find all price CSV files
csv_files = glob.glob(os.path.join(PRICE_DIR, "*_price.csv"))
if not csv_files:
print(f"No price CSV files found in {PRICE_DIR}", flush=True)
return
total_comments_counter = 0
for price_file in csv_files:
filename = os.path.basename(price_file)
if filename == "terra-luna_price.csv":
print("Skipping terra-luna_price.csv", flush=True)
continue
# Extract coin ID
coin_id = filename.split('_price')[0]
if coin_id not in COIN_MAP:
print(f"Skipping {coin_id}: Not in supported coin list", flush=True)
continue
print(f"Processing {coin_id}...", flush=True)
total_comments_counter = save_comments(coin_id, total_comments_counter)
print(f"Total comments fetched: {total_comments_counter}", flush=True)
if __name__ == "__main__":
main()
b) Function that updates price data
# Directory containing price CSV files
PRICE_DIR = "P2_Data_Analysis/Pricedata"
# Main process
def main():
# Find all CSV files in the price directory
csv_files = glob.glob(os.path.join(PRICE_DIR, "*_price.csv"))
if not csv_files:
print(f"No CSV files found in {PRICE_DIR}")
return
for file_path in csv_files:
filename = os.path.basename(file_path)
if filename == "terra-luna_price.csv":
print("Skipping terra-luna_price.csv")
continue
# Extract coin ID from filename
coin_id = filename.split('_price')[0]
print(f"Processing {coin_id}...")
update_csv_file(file_path, coin_id)
if __name__ == "__main__":
main()
For that part of our project, it was particularly helpful to stick to the data workflow guideline we learnt in the lecture. After conceptualizing a standardized tidy data structure, we decided that storing the data in csv files with naming conventions like "crpytocurrency_price.csv", "cryptocurrency_reddit_comments.csv", "cryptocurrency_alphavantage.csv" is sufficient for our purpose. We also more or less combined the continuous data collection with data cleaning, where the data is cleaned in a dataframe after collection before it is finally stored. This makes sense, as we have to update our data continuously anyway. Our code also includes many data validation elements before the actual sentiment analysis is done. For example, the program will notify the user if the data for a certain cryptocurrency selected is not among the csv files as expected.
To ensure that the original sentiment data is not affected by transformations like tokenization or stopword-removal, that step is currently done through a dataframe structure as well. However, we already realized that this is not super efficient and actually a waste of computing power. Therefore, we plan to create an additional data storage with preprocessed sentiment data so that only new sentiment data is preprocessed.
Functionalities of the Application
Our application will include the sentiment analysis models outlined in the diagram, and will offer a range of the most popular cryptocurrencies:
- BinanceCoin (BNB)
- Bitcoin (BTC)
- Cardano (ADA)
- Dogecoin (DOGE)
- Ethereum (ETH)
- Ripple (XRP)
- Solana (SOL)
- Terra Luna (LUNA) -> our basecase, available for the period from January 1, 2022 to June 30, 2022
The analysis timeframe available will be any range starting from April 30, 2024. This was a compromise we did because of difficulties in obtaining sentiment data from Reddit, which turned out to be very time consuming due to the slow API. Conversely, collecting daily price data was very easy to do.
Our Sentiment Analysis Models
An update on the dictionary method
From using the Loughran-McDonald dictionary, we discovered lower accuracy results than expected, with the model having 34.18% accuracy in determining whether a comment had positive, negative or neutral sentiment. As a result, we decided to test another dictionary called ‘AFINN’, which gave us a slightly improved accuracy of 36.69%. Furthermore, after Feng investigated the sentiment labels of the training data, we believe some of the comments may have been mislabelled, which made us conclude that many variables could have contributed to the low accuracy of the model. Although the results were still suboptimal, we believe the dictionary method is still highly valuable as it is the most transparent way of sentiment analysis. Nonetheless, we did not want to rely exclusively on the dictionary method, as we saw a lot of potential in more advanced methods. Generative AI Tools like Grok or ChatGPT are able to judge the underlying sentiment of a given sentence or news headline with almost 100% accuracy, and this is what we eventually want to aim for too.
Deep-learning method
To further advance our analysis, we decided to create several deep-learning models, which included the Long Short-Term Memory (LSTM), Transformer and Neural Bag of Words model, hoping for better results.
LSTM Model
We implemented a bidirectional LSTM with stacked layers, embedding capabilities, and dropout features. This architecture processes text sequentially while maintaining memory of previous content - similar to how someone reading a forum thread remembers earlier comments when interpreting new ones. The bidirectional approach allows the model to understand context from both directions, capturing nuances in expressions like "To the moon!" which change meaning depending on surrounding text. Our embedding layer groups similar words together in a 128-dimensional space, helping the model recognize related concepts even when wording varies. When tested, this model achieved 46.12% accuracy, significantly improving over dictionary methods. This enhancement stems from the LSTM's ability to analyze complete sentences, recognize context, and continuously refine its understanding through training - much like how humans improve at detecting sentiment with experience.
Transformer
Our transformer approach used pre-trained DistilBERT, which processes entire comments simultaneously rather than word-by-word. This model offers key advantages: It employs context-dependent word representations, meaning the same word (like "dump") receives different interpretations based on surrounding text. It also excels at connecting ideas mentioned far apart in lengthy comments. Most importantly, DistilBERT comes pre-trained on massive text datasets - like hiring an analyst with years of general language experience before specializing in crypto terminology. Its attention mechanism focuses on the most relevant words when determining sentiment. These capabilities delivered an improved 48.27% accuracy, showing that the transformer's sophisticated understanding of language better captured the complex sentiments in cryptocurrency discussions.
Neural Bag of Words (NBoW)
In this model, we started with a dataset we obtained from Kaggle containing cryptocurrency news with sentiment scores already attached to it and used this to start training our own model using a Fine Tuned model. With our pre-trained model, we can start to implement this on specifically Reddit comments of Bitcoin and obtain our own sentiment scores. Finally, we compared our results with the other methods to get a clearer idea of what sentiment looks like for us. In the end, we managed to get a train accuracy of 95.2% and a test accuracy of 86.4% which is quite high.
In terms of price prediction, we used a random forest model for this task and compared our results with the dictionary model. We found that there was a significant difference in their best lag days with NBoW having 12 best lag days and the dictionary method having only 4 days. However, both NBoW and Dictionary methods have similar corresponding accuracies with 63.51% and 63.64& respectively. Therefore, we thought of a way to improve this by introducing a time lag between sentiment and price because prices would often respond to sentiment changes with a certain delay.
import torch
import torch.nn as nn
import torch.optim as optim
import pandas as pd
import numpy as np
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
from sklearn.model_selection import train_test_split
import pickle
# Data preprocessing functions (skeleton)
def process_binary_sentiment_data(df):
# Convert sentiment column to dict and extract binary label
df = df.copy()
df['sentiment_dict'] = df['sentiment'].apply(eval)
df['label'] = df['sentiment_dict'].apply(lambda x: 1 if x['class']=='positive' else 0)
return pd.DataFrame({'text': df['text'], 'label': df['label']})
def tokenize_example(text, tokenizer, max_length=256):
# Tokenize and truncate
return tokenizer(text)[:max_length]
def process_data(df, vocab, max_length):
# Convert tokens to ids and pad
df['ids'] = df['tokens'].apply(lambda x: [vocab[token] for token in x])
df['padded_ids'] = df['ids'].apply(lambda x: x + [vocab['<pad>']] * (max_length - len(x)) if len(x) < max_length else x[:max_length])
X = torch.tensor(df['padded_ids'].tolist())
y = torch.tensor(df['label'].tolist())
return X, y
# Dataset class (skeleton)
class CryptoDataset(torch.utils.data.Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
def __len__(self):
return len(self.y)
def __getitem__(self, idx):
return {'ids': self.X[idx], 'label': self.y[idx]}
# NBoW model definition (skeleton)
class NBoW(nn.Module):
def __init__(self, vocab_size, embedding_dim, output_dim, pad_index):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_index)
self.fc = nn.Linear(embedding_dim, output_dim)
def forward(self, ids):
embedded = self.embedding(ids)
pooled = embedded.mean(dim=1)
return self.fc(pooled)
# Training and evaluation functions (skeleton)
def train(data_loader, model, criterion, optimizer, device):
model.train()
for batch in data_loader:
ids = batch['ids'].to(device)
label = batch['label'].to(device)
optimizer.zero_grad()
output = model(ids)
loss = criterion(output, label)
loss.backward()
optimizer.step()
# return average loss/accuracy (omitted)
def evaluate(data_loader, model, criterion, device):
model.eval()
with torch.no_grad():
for batch in data_loader:
ids = batch['ids'].to(device)
label = batch['label'].to(device)
output = model(ids)
loss = criterion(output, label)
# return average loss/accuracy (omitted)
if __name__ == "__main__":
# Set random seed
seed = 1029
np.random.seed(seed)
torch.manual_seed(seed)
# Load and preprocess data
df = pd.read_csv('cryptonews.csv')
processed_df = process_binary_sentiment_data(df)
# Tokenize and build vocabulary
tokenizer = get_tokenizer('basic_english')
processed_df['tokens'] = processed_df['text'].apply(lambda x: tokenize_example(x, tokenizer))
vocab = build_vocab_from_iterator(processed_df['tokens'], specials=['<unk>', '<pad>'])
vocab.set_default_index(vocab['<unk>'])
# Prepare train/val/test datasets and DataLoaders
train_data, test_data = train_test_split(processed_df, test_size=0.2, random_state=seed)
X_train, y_train = process_data(train_data, vocab, max_length=256)
train_dataset = CryptoDataset(X_train, y_train)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32)
# Initialize NBoW model, optimizer, loss
model = NBoW(len(vocab), 300, 2, vocab['<pad>'])
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# Training loop (simplified)
for epoch in range(5):
train(train_loader, model, criterion, optimizer, device)
# Save model and vocabulary
with open('nbow.pt', 'wb') as f:
torch.save(model.state_dict(), f)
with open('vocab.pkl', 'wb') as f:
pickle.dump(vocab, f)
Reflections on current progress
Seeing how we swiftly adapted and improved our approaches to create a better solution, we believe a few key elements aided us in this process. Firstly, given the project’s time constraint, we considered our strengths and experiences (mainly based on coding experience, which varied from none to deep-learning model training experience) and distributed the workload efficiently.
Despite the distribution of roles meant that some members coded significantly more than others, the use of Google Collab and GitHub not only allowed us to code collaboratively but ensured everyone was informed of the code written. Furthermore, our weekly group meetings facilitated fruitful discussions where we thrived off everyone’s thoughts and ideas from the data collection process up to the model training. This meant that everyone had a strong conceptual idea of the project and could contribute to the different perspectives that allowed us to reach our final idea.
Key Insights
Other key insights worth mentioning are especially those that came up during the coding process. As for some of us it was the first time to take on a larger coding project, we noticed that the actual work in creating such a project is taking place off the screen. It was very helpful to brainstorm sometimes before starting any coding, and collecting thoughts on what might be challenging to implement or where one could easily end up with spaghetti code if the process is not well thought through beforehand. Nowadays, once the structure is there, the vast amount of available packages and powerful AI-tools makes a lot of the work to be done very easy. But coming up with a robust structure in the first place can be very challenging.
For example, for our application, it was very essential to strictly separate the different functionalities of the program. We needed a data collection module on the one hand, and a data analysis module on the other hand. By laying out the structure early enough, we made sure that those two procedures are not intertwined, but only combined in one central python file that walks through the whole package we created. This is an example of the central function for obtaining the sentiment using different methodologies which return the sentiment scores for each item analyzed in a standardized format:
# Import sentiment analysis methods
from P2_Data_Analysis.Sentiment_Methods.mod_Loughran import analyze_loughran_mcdonald
from P2_Data_Analysis.Sentiment_Methods.mod_AFINN import analyze_afinn
# Sentiment analysis function
def analyze_sentiment(sentiment_dataframe, sentiment_column_name, sentiment_method):
"""
Analyze sentiment for each row in the dataframe and attach scores.
Args:
sentiment_dataframe (pd.DataFrame): DataFrame with sentiment data.
sentiment_column_name (str): Column containing text to analyze.
sentiment_method (str): Sentiment analysis method ('AFINN', 'LoughranMcDonald').
Returns:
pd.DataFrame: DataFrame with added 'method_score' and 'standardized_score' columns.
"""
df = sentiment_dataframe.copy()
# Map sentiment method to function
method_map = {
'AFINN': analyze_afinn,
'LoughranMcDonald': analyze_loughran_mcdonald
}
if sentiment_method not in method_map:
raise ValueError(f"Unsupported sentiment method: {sentiment_method}")
# Apply sentiment analysis
def get_scores(text):
score = method_map[sentiment_method](text)
standardized_score = 1 if score > 0 else -1 if score < 0 else 0
return pd.Series([score, standardized_score], index=['method_score', 'standardized_score'])
df[['method_score', 'standardized_score']] = df[sentiment_column_name].apply(get_scores)
return df
An example where we did not come up with a robust solution from the beginning on and is still to be improved is the following: there are many file paths in our project that are mentioned multiple times. In hindsight, it would have been much easier to create one central module that contains constant variables with all the file paths, so that they can easily be changed. Currently, we would have to change every single one of the file path’s occurrences, which is not only annoying, but also bound to create bugs in the code.
Our plan moving forward
Pending Challenges Down the Road
There are some challenges that we have to face in next days to build the intended minimum viable product from our project. This involves, for example, consolidating the results from the different sentiment analysis methods. While this was very intuitive for the dictionary methods, we built and trained the AI-based sentiment analysis methods separate from the other parts of the project. This means we still have to find a way to integrate them into the overall structure. Additionally, we also intend to build a user-friendly UI that outputs the results of each trading simulation in a comprehensive way. In terms of the trading simulation, it proves to be challenging to implement short-position. So far, we do not get sensible equity curves when also allowing for shorting the market if sentiment switches from good to bad.
But with various models and a lot of conceptualisation and work already being complete, we are now starting to finally piece together our trading simulator. We will continue to monitor and evaluate the performance of our sentiment analysis models by looking at the output with our own eyes as well as by creating more test datasets manually or using generative AI to ensure maximum reliability of the training data. Furthermore, we will explore the results of the trading simulations and assess whether sentiment based trading can actually be done in a profitable way that leads either to better performance than a simple buy-and-hold strategy or to less volatility given the same or a slightly lower return.